
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- 딥러닝학습
- 카카오 코테 메뉴리뉴얼
- 스타수열
- 프로그래머스 2차원동전뒤집기
- 과적합방지
- 프로그래머스 누적합
- 데이터축소
- 프로그래머스
- 자율성장 인공지능
- 2차원동전뒤집기
- 인공지능 경진대회
- 프로그래머스 2차원동전뒤집기 파이썬
- 인공신경망 학습
- 딥러닝파라미터
- 딥러닝 가중치 갱신
- 메뉴리뉴얼 파이썬
- 모델경량화
- 스타수열 파이썬
- 확률과우도
- 로지스틱 최대우도
- 프로그래머스광고삽입
- 프로그래머스 스타수열
- 딥러닝
- 카카오 메뉴리뉴얼
- k겹 교차검증
- 광고삽입 파이썬
- MLE
- 머신러닝 학습 검증
- AI경량화
- 비트마스킹
- Today
- Total
머신러닝 개발자의 러닝머신
[ML/DL] K-fold Cross Validation(k겹 교차검증) "검증의 신뢰도를 높이자" 본문
안녕하세요 😄
오늘은 교차검증과 가장 많이 사용되는 k-fold 기법에 대해서 알아보겠습니다.
데이터의 편향을 고려해 이를 방지하고 검증의 신뢰를 높이기 위한 방법인데요,
자세한 원리와 구조에 대해 알아보겠습니다.~
교차검증이란?
교차검증이란 데이터를 반복해서 여러 모델을 학습하여 모델의 성능을 평가하는 방법입니다.
조금 더 쉽게 말하자면 모델의 파라미터를 수정하는 과정에서 validation 데이터를 이용해 모델의 성능을 평가하게 되는데,
test set을 제외한 전체 데이터에서 validation과 train 데이터를 달리 하면서 학습과 평가를 진행하여 모델의 성능을 평가하는 방법입니다.
K-fold Cross Validation은 이러한 교차검증 방법론 중에 하나로, 가장 많이 사용하는 기법입니다.
이렇게 말로 설명하니 아직 어려운데요..! 바로 방식으로 진행되는지 알아보겠습니다.
K-fold Cross Validation(K-겹 교차검증)
K-fold cross validation은 test 데이터를 제외한 나머지 데이터를 k개의 폴드으로 분할 한 뒤 (k-1)개의 폴드를 train 데이터로, 나머지 하나를 validation 데이터로 사용해 모델을 학습하는 방법으로, 이러한 과정을 반복하면서 train과 validation 데이터로 사용할 폴드를 달리 하여 총 k개의 성능 지표를 얻는 방식으로 진행됩니다.
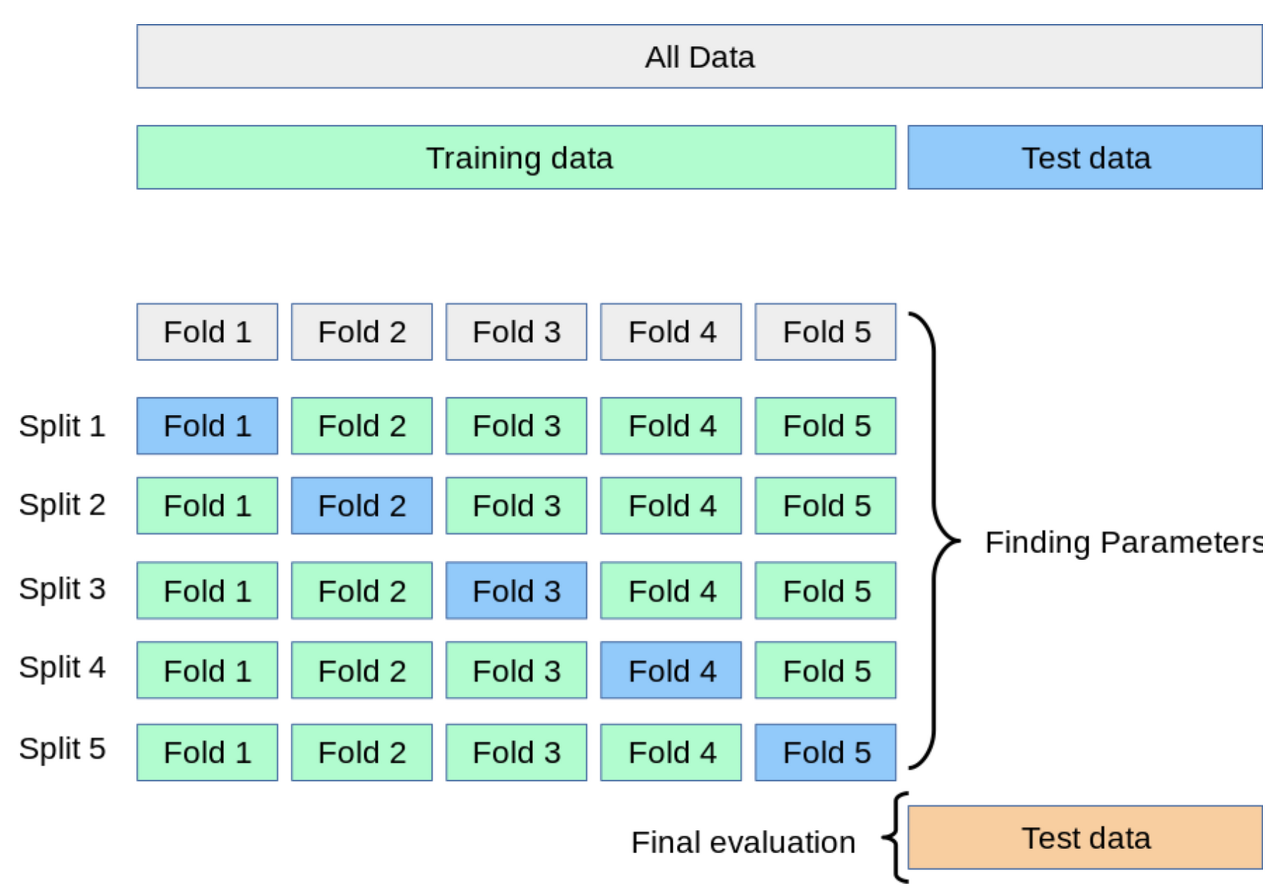
위의 그림과 같이 test set을 제외한 나머지 데이터를 train과 validation 데이터로 나누어 각각에 대해 모델을 학습하고 평가합니다.
이렇게 구해진 총 k개의 성능 평가 지표를 평균을 내어 최종 모델의 성능 지표를 결정합니다.
이렇게 결정된 모델의 학습 성능을 기반으로 모델을 수정하면서 최종 모델을 찾아나갑니다. 이렇게 최적의 모델을 찾았다면 최종 모델로 결정하여 train과 validation 데이터를 모두 합하여 모델을 학습하고, test set을 이용해 최종 평가를 수행합니다.
교차검증의 필요성
그렇다면, 굳이 이렇게 모델 훈련과 평가에 많은 시간을 들여서까지 교차검증을 수행하는 이유가 무엇일까요?
기계학습, 심층 학습에서 일반적으로 train set으로 모델을 훈련하고 test set으로 훈련된 모델의 성능 평가를 수행합니다.
이 때, test set으로 나누어진 데이터가 매우 편향된 데이터만 가지고 있다면 어떨까요?
train set으로 학습된 모델을 평가할 때 편향된 test set으로 인해 성능을 평가한 결과가 매우 안 좋거나 혹은 매우 좋게 나올 수 있습니다. 이렇게 잘못된 평가를 가지고 모델을 수정하는 과정을 반복하면 결국 편향된 test set에만 잘 작동하는 bias된 모델이 됩니다.
따라서 모델을 학습하고 평가할 때 사용하는 데이터를 어떻게 나누는 지에 따라서 결과가 달라지게 됩니다.
이러한 문제에서 출발한 것이 바로 교차검증입니다.
train set을 train과 validation set으로 분할하고 이를 교차변경 하면서 결과적으로 전체 데이터에 대해 모델의 학습과 평가를 수행해 일부 데이터에 편향된 학습을 방지하자는 것입니다.
정리하자면 k-겹 교차 검증은 데이터를 여러 개로 나누어 반복 학습과 검증을 수행하며, 하이퍼파라미터나 모델의 최적화 시, 최적의 조건을 찾는 데에 활용할 수 있습니다. 이 과정을 통해 기존에 일부 데이터에 편향된 모델이 만들어지는 문제를 해결할 수 있습니다.
교차검증의 장단점
교차검증의 장단점은 다음과 같습니다.
장점
- 특정 데이터에 대한 과적합(overfitting)을 방지할 수 있다.
-> 일반화된 모델을 얻을 수 있다. - 모든 데이터셋을 학습과 훈련에 사용할 수 있어 데이터 부족으로 인한 과소적합(underfitting)을 방지할 수 있다.
단점
- 데이터를 반복적으로 나누어 학습을 진행하여 소요되는 연산 비용이 증가한다.
이상으로 교차검증과 대표적인 기법인 k-fold 교차검증에 대해 알아보았습니다.🔎
훈련과 평가에 전체 데이터를 이용함으로써
특정 데이터에 편중된 모델이 만들어지는 것을 방지한다는 탁월한 기법입니다.
일반화된 모델을 만들때 적용해보면 좋은 방법인 것 같습니다.
그럼 오늘 포스트는 여기까지 입니다✨
Reference
'ML.AI > ML, DL' 카테고리의 다른 글
| [ML/DL] 모델 평가 지표(MAE, MSE, RMSE, Recall, Precision, F-Score, AUC) (0) | 2023.08.11 |
|---|---|
| [머신러닝]로지스틱 회귀(Logistic Regression) "범주데이터 분류는 확률 기반의 예측으로 치환한다" (0) | 2023.08.02 |
| [딥러닝] 인공신경망의 학습: 순전파와 역전파 (0) | 2023.05.09 |
| [딥러닝] 손실 함수(Loss Function) (0) | 2023.05.06 |
| [딥러닝] 활성화 함수(Activation Function) (0) | 2023.05.04 |



